前情回顾·AI网络攻击能力动态
安全内参4月15日消息,Anthropic在上周宣布,其Mythos预览版模型的初始发布仅限于“少数关键行业合作伙伴”,以便这些合作方有时间为该模型的应用做好准备。该公司表示,这一模型“在网络安全任务上能力惊人”。
如今,英国政府人工智能安全研究所(AISI)已发布对该模型网络攻击能力的初步评估,为Anthropic的说法提供了独立公开验证。
AISI的研究结果显示,在单项网络安全任务测试中,Mythos与其他近期发布的前沿模型相比并未表现出显著差异。然而,Mythos可能凭借其将多个任务高效串联为多步骤攻击序列的能力,在需要完整渗透系统的场景中展现出优势。
“最后的幸存者”终究倒下
自2023年初起,AISI一直通过专门设计的“夺旗赛”(CTF)对各类AI模型进行测试。当时,GPT-3.5 Turbo在完成该机构较为基础的“学徒”级任务时表现吃力。此后,各大模型性能持续提升。如今,Mythos预览版已能够完成超过85%的同类学徒级任务。
尽管这一成绩刷新了AISI“夺旗赛”测试的最高纪录,但近期发布的竞争模型,如GPT-5.4,以及Anthropic自家的Opus 4.6和Codex 5.3,在多个难度等级的测试中表现相近,准确率差距通常在5%至10%之间。因此,这一性能提升似乎不足以完全解释Anthropic对Mythos预览版采取严格限制发布的策略。
不过,在名为“最后的幸存者”(TLO)的测试环境中,Mythos展现出更为突出的网络攻击潜力。该环境由AISI构建,用于模拟一次包含32个步骤的数据提取攻击,目标是企业网络。测试要求“在多个主机与网络分段之间连续执行数十个步骤”,旨在还原一名训练有素的人类通常需要约20小时才能完成的持续性攻击过程。
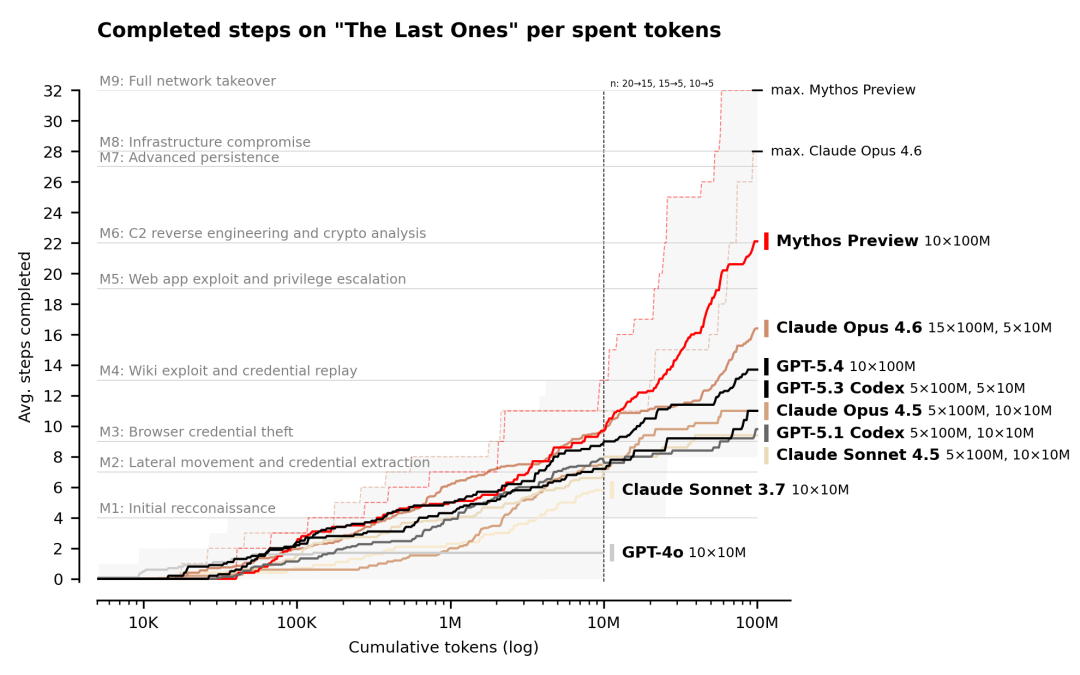
图:Mythos首次成功完成32步的TLO挑战,其10次测试的平均完成步数为22步
AISI表示,在这项测试中,Mythos超越了此前所有模型,成为“首个能够从头到尾完整完成整个攻击流程的模型”。尽管Anthropic的这款新模型在10次尝试中仅成功了3次,但把全部10次尝试一起计算在内,Mythos预览版平均每次仍能完成32个渗透步骤中的22个,明显高于Claude4.6平均仅完成16个步骤的表现。
AISI表示,在这一测试中,Mythos超越了此前所有模型,成为“首个能够从头到尾完成此项测试的模型”。尽管Anthropic的这款新模型在10次尝试中仅有3次成功完整跑通整个32步渗透流程,但将全部10次尝试纳入统计后,Mythos预览版平均每次仍能完成22个渗透步骤,明显高于Claude 4.6平均仅完成16个步骤的表现。
不过,Mythos预览版仍存在一定局限。AISI指出,在名为“冷却塔”的测试中,该模型表现依然不理想。这项测试包含7个步骤,难度更高,旨在模拟对发电厂控制软件的干扰行为。与此同时,AISI认为,“随着推理计算资源超过本次测试设定的一亿词元预算,模型表现预计仍将进一步提升”。
防护薄弱的小型系统需提高警惕
总体来看,Mythos在“最后的幸存者”测试中的表现表明,该模型“至少具备在已获得网络访问权限的前提下,对防御薄弱且存在漏洞的小型企业系统实施自动化攻击的能力。”
不过,AISI同时提醒,其模拟环境缺乏现实关键系统中常见的主动防御机制和防护工具。此外,“最后的幸存者”测试刻意设置了特定漏洞,而这些漏洞在现实系统中未必存在。测试过程中也未对模型被检测到的情况施加惩罚,而在现实环境中,一旦被发现,渗透行动往往会迅速失败。
基于上述因素,AISI表示,目前尚无法确定“防护完善的系统”是否会被Mythos预览版的自动化攻击攻破。但该机构也警告,随着未来模型能力达到或超过Mythos,系统安全设计者同样需要借助AI技术来提升防御能力。
参考资料:https://arstechnica.com/ai/2026/04/uk-govs-mythos-ai-tests-help-separate-cybersecurity-threat-from-hype/
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。